几天前,美国OpenAI公司发布的AI视频生成模型Sora,引发全球关注。
而就在Sora爆火的这几天,一张OpenAI的创始人阿尔特曼和李一舟,“中美两大AI巨头”的恶搞图在网络疯传……
热度还没下去呢……这两天谷歌又发布了号称全球最强开源大模型Gemma!
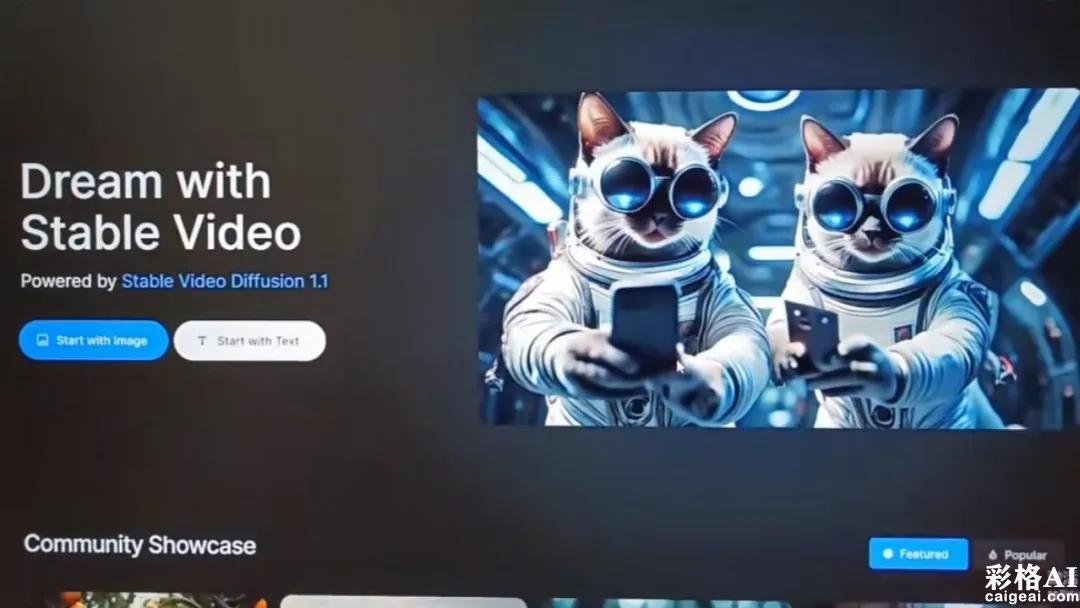
就在近期,Stability AI的Stable Video官方正式上线!Stability AI推出了Stable Video并开启了公测,其背后的技术正是Stable Video Diffusion 1.1。令人遗憾的是,由于Sora的发布,Stable Video Diffusion 1.1并未掀起讨论的热潮。
就在昨天Stable Diffusion 3突然发布,显然是不希望被其他竞争对手抢了热点。不仅仅是Stability AI近期有大动作,据小道消息说Midjourney马上也要发布视频以及V7!
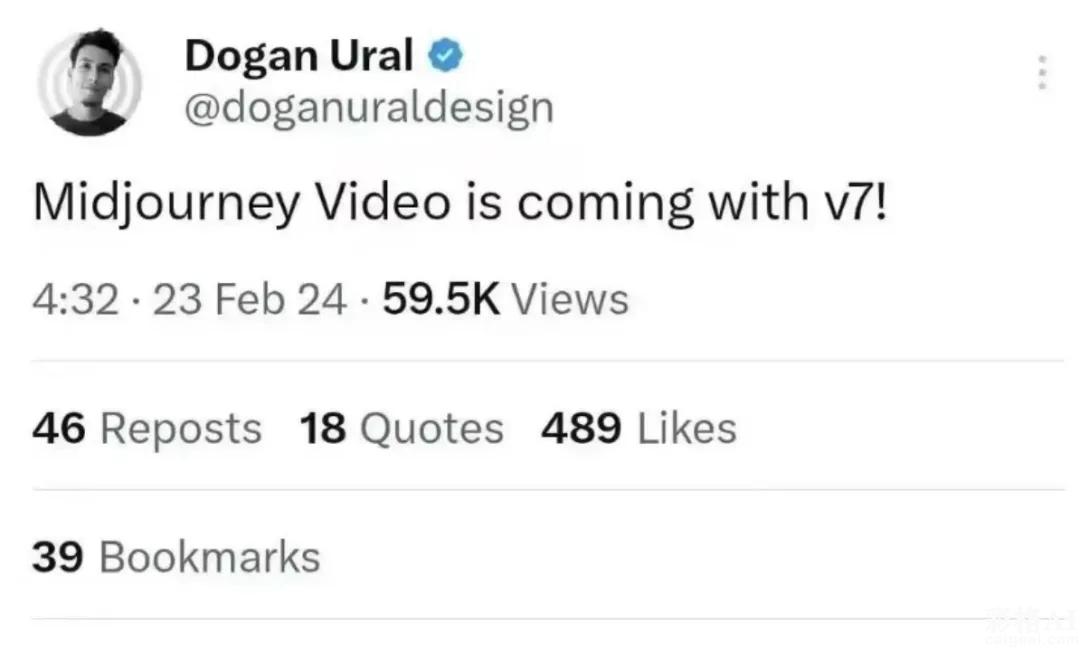

Stable Diffusion 3的最大亮点莫过于其采用的Diffusion Transformer架构,这不禁让人联想到OpenAI新发布的文生视频模型Sora也同样基于这一架构,真可谓“英雄所见略同”,验证了“Transformer is all you need”的真理。
事实上,SDXL的技术报告也曾提及Transformer的使用,但当时并未展现出明显优势。然而,开发者们坚信通过精细调整参数并应用更大规模的Transformer,定能取得突破。因此,Stable Diffusion 3采用Transformer架构并非随波逐流,而是有备而来。这也解释了为何之前的SDXL并未命名为SD3,因为SD3注定采用全新架构,独步舞台。
Stable Diffusion 3的模型参数从800M到8B,最大的模型到了8B,最大模型8B,该模型为用户提供丰富可扩展性和质量选项,满足多样化创意需求。这是不是意味着文生图的模型参数量从此都要跃上一个新的台阶了,普通玩家的门槛要高了。
通过融合扩散变压器架构与流量匹配,Stable Diffusion 3展现卓越性能。尽管尚未广泛应用,但现已开放早期预览候补名单。
此预览阶段对于收集反馈、提升模型性能与安全性至关重要,如同前序模型一般。技术报告即将发布,敬请期待。
现在可以加入候补名单了
Stable Diffusion 3申请访问权限地址:https://stability.ai/news/stable-diffusion-3



地址:https://www.stablevideo.com
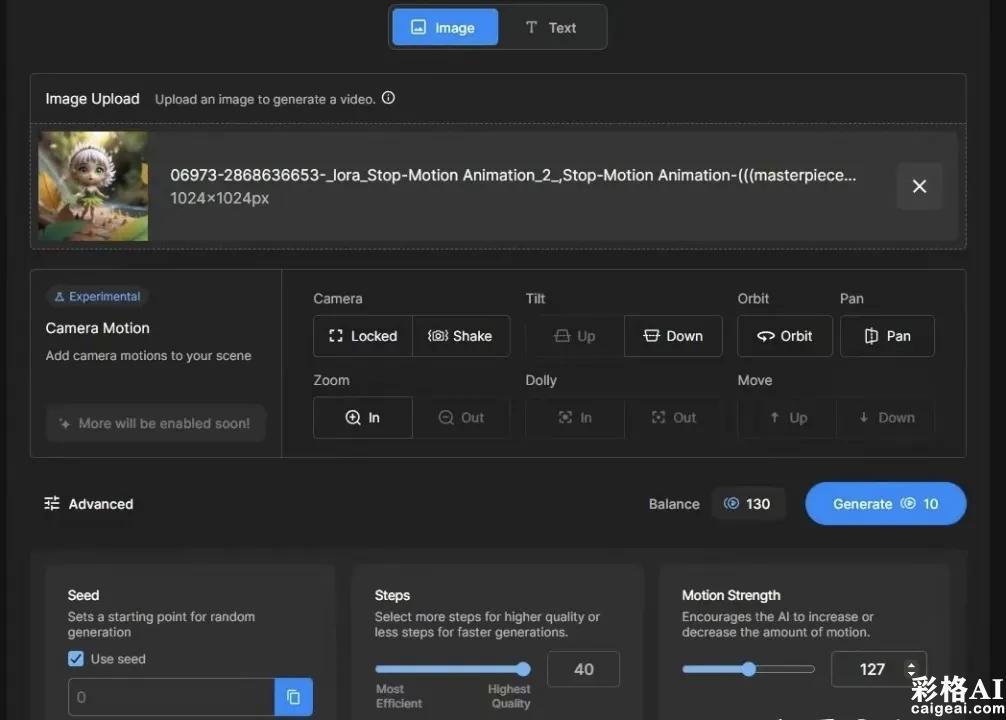
在这里提醒下大家:除了每日150个赠送积分外,还新增了积分购买选项,目前提供两种积分包(积分永久有效)
500积分/$10,大概50条视频
3000积分/$50,大概300条视频
总的体验下来的感觉,如果之前Sora没有出来之前,我真的还觉得挺不错的,但是我用完Sora之后,单单从效果上来说的话,的确稍微差点意思。还有就是服务器稍微有点不稳定,应该是刚正式开放公测,人多!
尽管SVD1.1取得了显著进步,但与Sora相比,仍存在不少遗憾。具体而言:
SVD 1.1生成的视频片段往往较为短暂,鲜有超过4秒的时长。
该模型在生成过程中容易偏向静态或缓慢移动的图像,难以捕捉瞬息万变的动态场景。
在交互性和控制方面,SVD 1.1目前尚不支持通过文字指令直接驾驭视频内容的创作,其功能多局限于静态图像向视频的转化。
当涉及到文字内容的生成时,特别是在需要清晰、准确呈现文字信息的场合,SVD 1.1往往难以胜任。
在视频中人物占比较小的情况下,SVD 1.1可能难以精确刻画人物的面部细节。
新年伊始,科技领域风起云涌,人工智能领域更是硝烟弥漫,显然今年又将是一个变革与竞争并存的年份。
我们普通人,一定要努力跟上时代,积极拥抱新知,砥砺前行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。