对用户而言,只要提供一段文本、一张草图,甚至是一个想法,Genie就会完成剩下的工作,生成一款2D游戏。谷歌称,Genie可以将任何图像转换成可互动的2D世界。
人类一共有九大艺术,分别是绘画、雕刻、建筑、音乐、文学、舞蹈、戏剧、电影、最后一个是游戏,现在已经全部都被AI攻克了。
从2023年开始,人工智能成为最有潜力的朝阳产业,类似于这种交互环境的游戏,没有什么是AI做不到的。
随着科技巨头谷歌的强势加入,世界模型领域瞬间风起云涌,各大玩家纷纷摩拳擦掌,欲争夺这一新兴领域的领导地位。然而,究竟谁能引领世界模型的风向,成为行业的领头羊,目前仍是众说纷纭,难下定论。
Sora的视频生成方式与世界模型所追求的因果预测大相径庭。从Sora发布的视频来看,虽然其高保真的效果让人眼前一亮,但在模拟物理规律方面似乎略显薄弱,难以让人看到其交互能力的影子。
与此同时,谷歌推出的新型世界模型Genie,却在交互性上大放异彩。这款模型能够精准推断出生成环境中的潜在动作,为用户带来更加沉浸式的体验。然而,在视频的真实性和清晰度方面,Genie似乎还未能达到Sora那样的卓越水平。

据谷歌发布的论文揭示,Genie的强大功能得益于其独特的三重结构。首先,一个简单的潜在动作模型,能够精准推断每一对帧之间的微妙变化;其次,一个视频分词器将原始的视频帧转化为离散的标志(token),使得模型能够更高效地处理信息;最后,一个动态模型则根据潜在动作和过去的帧token来预测下一帧的内容,为用户呈现出连贯而流畅的游戏画面。
从谷歌发布的演示视频来看,Genie的表现令人惊艳。只需输入一张动漫人物闯关的图片,Genie便能生成背景变换丰富、人物跳跃连贯且踩点精准的视频,其动作的流畅度和合理性让人叹为观止。即便输入的是真实世界的图片,Genie也能让其中的人物和动物作出合理的跳跃或移动动作,尽管像素略显粗糙,但这并不影响其展现出的巨大潜力。
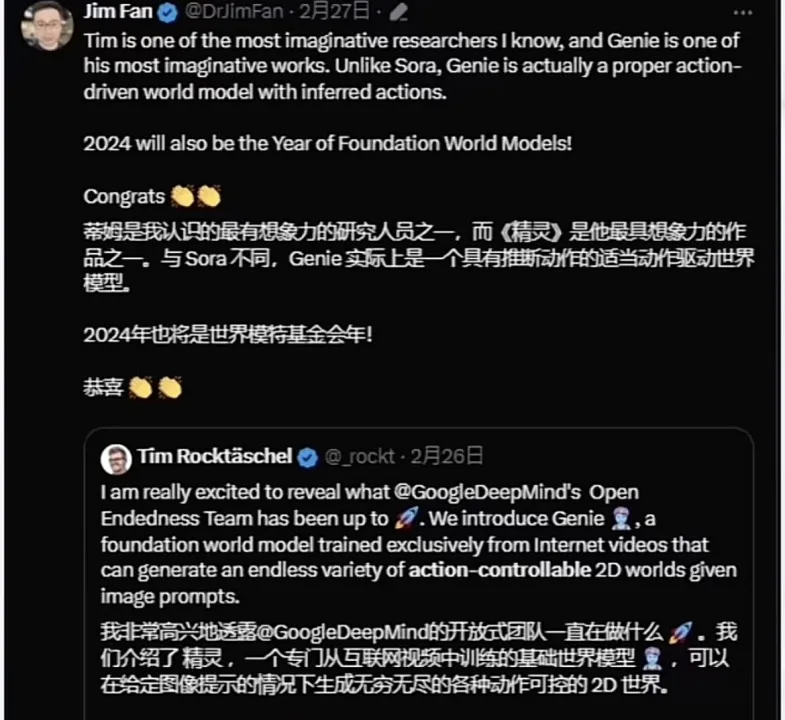
英伟达科学家Jim Fan表示,蒂姆是我认识最有想象力的研究员之一,而Genie(精灵)是他最具想象力的作品之一。与Sora不同,Genie实际上是一个具有推断动作的适当动作驱动世界模型。
尽管目前“Genie”尚处于萌芽阶段,主要局限于构建简单的平台类游戏,但其背后所蕴含的技术力量已足以让人惊叹。它不仅能依据用户提供的图像资料生成独具特色的平台游戏,还能巧妙融合文本、图像、音乐等多元素材,为玩家带来前所未有的游戏体验。
“Genie”的诞生,不仅为游戏界注入了新的活力,更为我们展现了一个充满无限可能的虚拟世界。
有可能我们的世界就是从一张图片开始的。以后游戏开发效率大大提升,就不需要那么多工程师了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。