我们在写论文或者做其他一些专业研究时,往往会去阅读国外的资料,那就需要对这些资料进行翻译,方便我们学习和使用。
但这些资料具有一定的专业性和学术性,但一般的翻译工具往往不能很好地传达原文的学术语调。翻译出来的文章会有股“AI味”。
但如果我们让GPT扮演特定的翻译角色,就可以为我们准确翻译并分析专业资料。我们以一份AIGC论文资料为例,原文如下:
Transformer. Transformer is the backbone architecture for many state-of-the-art models,
such as GPT-3 [9], DALL-E-2 [5], Codex [2], and Gopher [39]. It was first proposed to solve the
limitations of traditional models such as RNNs in handling variable-length sequences and contextawareness. Transformer architecture is mainly based on a self-attention mechanism that allows
the model to attend to different parts in a input sequence. Transformer consists of an encoder and
a decoder. The encoder takes in the input sequence and generates hidden representations, while
the decoder takes in the hidden representation and generates output sequence. Each layer of the
encoder and decoder consists of a multi-head attention and a feed-forward neural network. The
multi-head attention is the core component of Transformer, which learns to assign different weights
to tokens according their relevance. This information routing method allows the model to be better
at handling long term dependency, hence, improving the performance in a wide range of NLP tasks.
Another advantage of transformer is that its architecture makes it highly parallelizable, and allows
data to trump inductive biases [40]. This property makes transformer well-suited for large-scale
pre-training, enabling transformer based models to become adaptable to different downstream
tasks.
3.1.2 Pre-trained Language Models. Since the introduction of the Transformer architecture, it has
become the dominant choice in natural language processing due to its parallelism and learning
capabilities. Generally, these transformer based pre-trained language models can be commonly
classified into two types based on their training tasks: autoregressive language modeling and
masked language modeling [41]. Given a sentence, which is composed of several tokens, the
objective of masked language modeling, e.g., BERT [42] and RoBERTa [43], refers to predicting the
probability of a masked token given context information. The most notable example of masked
language modeling is BERT [42], which includes masked language modeling and next sentence
J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018.
Fig. 4. Categories of pre-trained LLMs. Black line represents information flow in bidirectional models, while
gray line representas left-to-right information flow. Encoder models, e.g. BERT, are trained with context-aware
objectives. Decoder models, e.g. GPT, are trained with autoregressive objectives. Encoder-decoder models, e.g.
T5 and BART, combines the two, which use context-aware structures as encoders and left-to-right structures
as decoders.
prediction tasks. RoBERTa [43], which uses the same architecture as BERT, improves its performance
by increasing the amount of pre-training data and incorporating more challenging pre-training
objectives. XL-Net [44], which is also based on BERT, incorporates permutation operations to change
the prediction order for each training iteration, allowing the model to learn more information
across tokens. While autoregressive language modeling, e.g., GPT-3 [9] and OPT [45], is to model
the probability of the next token given previous tokens, hence, left-to-right language modeling.
Different from masked language models, autoregressive models are more suitable for generative
tasks. We will introduce more about autoregressive models in Section 4.1.1.
第一步:我们发送提示词,明确GPT的专业角色和任务
您是一位优秀的[AIGC]学者和翻译家,受过将学术文献从英语翻译成中文的培训。接下来我会提供您一段英文学术资料。您的目标是提供准确、连贯的译文,保持原意和学术严谨性。任务指导:1. 将以下文本从英语翻译成中文,同时保持学术语调、特定领域术语和整体连贯性。译文应准确反映原文意思。2. 根据需要查阅特定领域的词汇表、字典或参考资料,以确保专业术语的准确翻译。3. 再次检查译文,确保译文保持学术腔调,准确传达原文内容,并遵守学术写作惯例。
第二步:发送需要翻译的英文资料
我们可以将以上需要啊翻译的原文资料文本复制粘贴后发给GPT。
可以看下翻译效果。ChatGPT把人工智能领域的前馈神经网络和自注意力等专业名词都翻译出来了。
Transformer. Transformer是许多最先进模型的骨干架构,如GPT-3 [9]、DALL-E-2 [5]、Codex [2]和Gopher [39]。它最初被提出来解决传统模型(如RNNs)在处理可变长度序列和上下文感知方面的局限性。Transformer架构主要基于一种自注意机制,使得模型能够关注输入序列中的不同部分。Transformer由编码器和解码器组成。编码器接收输入序列并生成隐藏表示,而解码器接收隐藏表示并生成输出序列。编码器和解码器的每一层都包括多头注意力和前馈神经网络。多头注意力是Transformer的核心组件,它学会根据它们的相关性为令牌分配不同的权重。这种信息路由方法使得模型更擅长处理长期依赖,从而提高在广泛的NLP任务中的性能。Transformer的另一个优势是其架构使其高度可并行化,并允许数据胜过归纳偏见 [40]。这一特性使得Transformer非常适用于大规模预训练,使得基于Transformer的模型能够适应不同的下游任务。
3.1.2 预训练语言模型。自从引入Transformer架构以来,由于其并行性和学习能力,它已成为自然语言处理中的主导选择。一般而言,基于Transformer的这些预训练语言模型可以根据它们的训练任务通常分为两类:自回归语言建模和掩码语言建模 [41]。给定一个由多个标记组成的句子,掩码语言建模的目标,例如BERT [42]和RoBERTa [43],是预测给定上下文信息的掩码标记的概率。掩码语言建模的最显著例子是BERT [42],它包括掩码语言建模和下一句预测任务。RoBERTa [43]使用与BERT相同的架构,通过增加预训练数据的量并引入更具挑战性的预训练目标来提高性能。XL-Net [44]也基于BERT,通过引入排列操作改变每个训练迭代的预测顺序,使模型能够跨标记学习更多信息。而自回归语言建模,例如GPT-3 [9]和OPT [45],是对给定先前标记的下一个标记的概率进行建模,因此是左到右的语言建模。与掩码语言模型不同,自回归模型更适用于生成性任务。我们将在第4.1.1节介绍更多关于自回归模型的内容。
第三步:针对翻译完成的资料进一步提出需求,如分析、总结等;
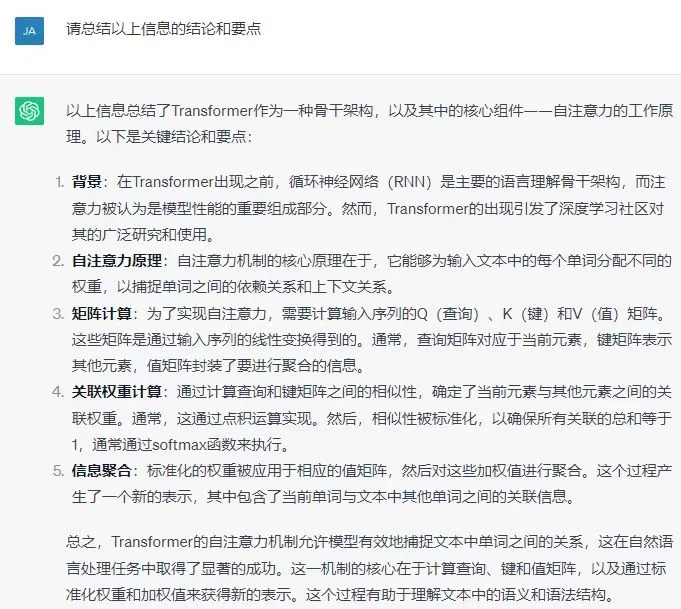
这样就能够解决你所有专业资料翻译的问题了。
技能平移,举一反三
除了学术翻译之外,我们也将此方法用于翻译新闻、小说等领域。核心思路是我们需要设定要角色、情境和任务。
比如翻译新闻时,我们可以参考如下提示词:
你是一位精通简体中文的专业翻译,曾参与《纽约时报》和《经济学人》中文版的翻译工作,因此对于新闻和时事文章的翻译有深入的理解。我希望你能帮我将以下英文新闻段落翻译成中文,风格与上述杂志的中文版相似。规则:- 翻译时要准确传达新闻事实和背景。- 保留特定的英文术语或名字,并在其前后加上空格,例如:"中 UN 文"。- 分成两次翻译,并且打印每一次结果:1. 根据新闻内容直译,不要遗漏任何信息2. 根据第一次直译的结果重新意译,遵守原意的前提下让内容更通俗易懂,符合中文表达习惯
原文如下:
Scientists in Scotland are using robotic subsea gliders to check ocean currents for signs of climate collapse.
They are monitoring the “conveyor belt” which carries warm and cool water between the Caribbean and the Arctic.
Scientists fear a weakening of the system would have a devastating effect across large parts of the planet.
The Scottish Association for Marine Science (Sams) at Oban is deploying the robots on autonomous missions between the UK and Iceland over five months.
Atlantic circulation is important for distributing tropical heat across the world and keeps northern Europe at a more temperate climate than other locations on the same latitude.
How currents affect global temperatures
Its collapse is referred to as one of the climate “tipping points” and there is some research to suggest it might be very slowly weakening.
Because it fluctuates, experts say circulation needs to be monitored closely over several decades for any firm conclusions to be made about its strength.
Modelling suggests that although its collapse would be catastrophic, it’s highly unlikely this would happen in the 21st Century.
Helen Smith
Oceanographer and researcher Dr Helen Smith says the oceans are understudied
The robotic gliders dive to depths of 1,000m (3,281 ft) gathering data about water temperature, oxygen and salt levels.
Each travels at a speed of half a mile an hour and resurfaces every five to six hours when communicating with the research team via satellite.
Oil industry faces ‘moment of truth’ at climate summit
Is the world warming faster than we expected?
Sailing to school and the daily issues of climate change
Oceanographer Helen Smith says the marine environment is incredibly understudied because most historical observations are confined to the area surrounding a ship at a single point in time, usually the summer.
Dr Smith adds: “We can send these out to measure water all year round in places that we couldn’t get to.”
The current system is called the Atlantic Meridional Overturning Circulation (Amoc) and has been measured and modelled since 2004.
As the warm water moves north it cools which increases the salt density causing it to sink into the deeper ocean.
Glider on deck
Oceanographers prepare the glider for deployment in the North Atlantic
That cooler water then flows southwards, completing the cycle.
The Met Office has warned that increases in polar ice melt, along with the warming climate, mean the system needs to be closely monitored.
Prof Mark Inall, an expert in physical oceanography at Sams, describes the heat in the North Atlantic as a vital part of the earth’s climate system.
He added: “It transports huge quantities of heat from the tropics to the polar regions and a lot of that heat comes into the atmosphere which makes it a very vigorous, stormy place, particularly around the UK.”
As well as monitoring the Amoc, the data gathered by gliders helps improve scientists’ understanding of how the atmosphere is affected by changes in the ocean.
It also provides near real-time data for shorter term weather forecasting.
Other robotic technology being used includes an autonomous boat which uses sonar to collect ocean pressure data from sensors on the sea bed.
翻译结果:
苏格兰科学家正借助水下机器人滑翔器检查海洋流动,以寻找气候崩溃的迹象。
他们正在监测“输送带”,这是在加勒比海和北极之间传递温暖和凉爽水的系统。
科学家担心该系统的减弱将在地球的大部分地区产生毁灭性影响。
奥本的苏格兰海洋科学协会(Sams)正在五个月的时间里部署这些机器人,进行英国和冰岛之间的自主任务。
大西洋环流对于将热带热量分布到世界各地,并使北欧保持相对温和的气候非常关键。
水流如何影响全球温度
其崩溃被称为气候“临界点”之一,一些研究表明它可能在非常缓慢地减弱。
由于系统波动,专家表示需要在数十年内密切监测环流以得出对其强度的结论。
建模显示,尽管其崩溃将是灾难性的,但在21世纪发生这种情况的可能性极小。
海洋学家和研究员海伦·史密斯博士表示,由于大多数历史观测仅限于单一时间点附近的船只周围区域,通常是夏季,因此海洋环境研究不足。
史密斯博士补充说:“我们可以派遣这些滑翔器全年在我们无法到达的地方测量水质。”
该系统被称为大西洋经向翻转环流(Amoc),自2004年以来一直在进行测量和建模。
随着温暖水向北移动,它冷却,增加盐密度导致其沉入更深的海洋。
滑翔器上甲板
海洋学家为在北大西洋投放滑翔器做准备
冷却的水然后向南流动,完成整个循环。
英国气象局警告称,随着极地冰融化的增加以及气候变暖,有必要密切监测该系统。
奥本的苏格兰海洋科学协会的物理海洋学专家马克·因奥尔教授将北大西洋的热量描述为地球气候系统的重要组成部分。
他补充说:“它将大量热量从热带地区输送到极地地区,其中很多热量进入大气层,使其成为一个非常有活力、多风暴的地方,特别是在英国周围。”
除了监测Amoc外,滑翔器收集的数据有助于提高科学家对海洋变化对大气的影响的理解。
它还为短期天气预报提供几乎实时的数据。
正在使用的其他机器人技术包括一艘自主船,该船使用声纳从海床上的传感器收集海洋压力数据。
© 版权声明
文章版权归作者所有,未经允许请勿转载。